Oracle APEX - Parsing fixed-width formatted files

Oracle APEX Developer (Insum) from Paris Contributor of Flows for APEX Passionate about APEX and web development.
Introduction
This blog post focuses on how to parse a fixed-width formatted file using Oracle's APEX, SQL and PL/SQL to make it as efficient as possible.
What is a fixed-width formatted file?
The fixed-width format is a defined format in which data is not separated by a separator as in a CSV, but has a fixed length and position.
Here is a basic example
ID FIRST_NAME LAST_NAME CITY COUNTRY
0000001LOUIS MOREAUX PARIS FRANCE
0000002JOHN SMITH CHICAGO UNITED STATES
0000003JANE DOE LONDON UNITED KINGDOM
As you can see, there are five columns, but no separators. Each column has a fixed width.
| Column | Size |
| ID | 7 characters |
| FIRST_NAME | 20 characters |
| LAST_NAME | 20 characters |
| CITY | 20 characters |
| COUNTRY | 30 characters |
How to read it?
There are many articles and examples on how to read XLSX or CSV files, and it can even be done declaratively using the data load definition. However, I haven't found anything about the fixed-width format. This is probably because it's an old format, less used today, but if you have to communicate with existing systems that only understand this format, you have no choice.
The first challenge is to extract the list of lines from the file. To do this, we'll use four different options and compare them.
APEX_DATA_PARSER
apex_data_parser is a useful package when it comes to parsing files in APEX (or in the Oracle database). It can parse XLSX, CSV, XML and JSON and has always been my first approach to reading files.
In this particular case, we'll consider that our text file is a CSV and that the apex_data_ parser.parse function will give you the whole row in column col001 with the following query
select col001
from table (
apex_data_parser.parse(
p_content => l_blob_content,
p_file_name => 'dataset.txt',
p_file_type => apex_data_parser.c_file_type_csv
)
)
At this point, the col001 will contain something like this
| COL001 |
| 0000001LOUIS MOREAUX PARIS FRANCE |
| 0000002JOHN SMITH CHICAGO UNITED STATES |
| 0000003JANE DOE LONDON UNITED KINGDOM |
How do you divide this data into separate columns? We can use the SQL function substr() to do just that.
select rtrim(substr(column_value, 1, 7)) as id,
rtrim(substr(column_value, 8, 20)) as first_name,
rtrim(substr(column_value, 21, 20)) as first_name,
rtrim(substr(column_value, 41, 30)) as city,
rtrim(substr(column_value, 71, 30)) as country
from (
select col001 as column_value
from table (
apex_data_parser.parse(
p_content => l_blob_content,
p_file_name => 'dataset.txt',
p_file_type => apex_data_parser.c_file_type_csv
)
)
) raw_data;
The output of this query will be
| ID | FIRST_NAME | LAST_NAME | CITY | COUNTRY |
| 0000001 | LOUIS | MOREAUX | PARIS | FRANCE |
| 0000002 | JOHN | SMITH | CHICAGO | UNITED STATES |
| 0000003 | JANE | DOE | LONDON | UNITED KINGDOM |
You'll have noticed that we also use the rtrim() function to eliminate extra space characters at the end of each value.
APEX_STRING
Another option is to use the apex_string.split() function, in this case, the query will be
select rtrim(substr(column_value, 1, 7)) as id,
rtrim(substr(column_value, 8, 20)) as first_name,
rtrim(substr(column_value, 21, 20)) as first_name,
rtrim(substr(column_value, 41, 30)) as city,
rtrim(substr(column_value, 71, 30)) as country
from (
select column_value
from table (apex_string.split(l_clob_content))
) raw_data;
The main difference is that we will have to first convert our file to a clob.
JSON_TABLE
The third option evaluated here is to use the json_table() to read the file, the query will be
select rtrim(substr(column_value, 1, 7)) as id,
rtrim(substr(column_value, 8, 20)) as first_name,
rtrim(substr(column_value, 21, 20)) as first_name,
rtrim(substr(column_value, 41, 30)) as city,
rtrim(substr(column_value, 71, 30)) as country
from (
select val as column_value
from json_table ('["'
|| replace(l_clob_content, chr(10), '","')
|| '"]', '$[*]'
columns (
val varchar2(4000) path '$'
)
)
) raw_data;
DBMS_LOB
The last option evaluated here (I'm sure there are others), is using the dbms_lob which is a package that provides several handy programs to handle blobs, clobs and bfiles. The code used to read the file is the following one
declare
l_clob_content clob;
l_offset number := 1;
l_amount number := 32767;
l_len number;
l_buffer varchar2(32767);
i pls_integer := 1;
begin
l_len := dbms_lob.getlength(l_clob_content);
begin
if (dbms_lob.isopen(l_clob_content) != 1) then
dbms_lob.open(l_clob_content, 0);
end if;
l_amount := instr(l_clob_content, chr(10), l_offset);
while (l_offset < l_len)
loop
dbms_lob.read(l_clob_content, l_amount, l_offset, l_buffer);
dbms_output.put_line(l_buffer);
end loop;
if (dbms_lob.isopen(l_clob_content) = 1) then
dbms_lob.close(l_clob_content);
end if;
end;
end;
Which option is the fastest?
To answer this question, we need to compare the four approaches with the same data set. To do this, I generated a TXT file containing 100,000 rows for the 5 columns mentioned above. I created it using a simple table, the amazing Data Generator utility and the apex_data_export package. I may write another blog post about it. If you're interested, leave a comment!
Database table for the timing
All the credit for that goes to Carsten Czarski, I simply reuse what he built in this Oracle Live SQL script.
create table timings(
action varchar2(200) primary key,
start_time timestamp,
end_time timestamp
);
Oracle APEX application
I created a simple Oracle APEX page to manage the file upload, containing a file browse item, the process for reading the file content and a report showing the results.
Here is the PL/SQL code of the page process
declare
l_clob_content clob;
l_blob_content blob;
type t_rec is record(
id fixed_width.id%type,
first_name fixed_width.first_name%type,
last_name fixed_width.last_name%type,
city fixed_width.city%type,
country fixed_width.country%type);
type t_tab is table of fixed_width%rowtype;
l_rec t_rec;
l_tab t_tab;
l_offset number := 1;
l_amount number := 32767;
l_len number;
l_buffer varchar2(32767);
i pls_integer := 1;
begin
-- Delete the timings table before each run
delete from timings;
-- Get the blob and the clob from the temporary table
select blob_content, to_clob(blob_content)
into l_blob_content, l_clob_content
from apex_application_temp_files
where application_id = :app_id
and name = :p1_file;
-- APEX_STRING
-- Insert the start time in the timings table
insert into timings values ('APEX_STRING', systimestamp, null);
-- Bulk collect the file content
select rtrim(substr(column_value, 1, 7)) as id,
rtrim(substr(column_value, 8, 20)) as first_name,
rtrim(substr(column_value, 21, 20)) as first_name,
rtrim(substr(column_value, 41, 30)) as city,
rtrim(substr(column_value, 71, 30)) as country
bulk collect into l_tab
from (
select column_value
from table (apex_string.split(l_clob_content))
) raw_data;
-- Update the timings table with the end time
update timings set end_time = systimestamp where action = 'APEX_STRING';
-- Clean up the collection
l_tab := t_tab();
-- APEX_DATA_PARSER
-- Insert the start time in the timings table
insert into timings values ('APEX_DATA_PARSER', systimestamp, null);
-- Bulk collect the file content
select rtrim(substr(column_value, 1, 7)) as id,
rtrim(substr(column_value, 8, 20)) as first_name,
rtrim(substr(column_value, 21, 20)) as first_name,
rtrim(substr(column_value, 41, 30)) as city,
rtrim(substr(column_value, 71, 30)) as country
bulk collect into l_tab
from (
select col001 as column_value
from table (
apex_data_parser.parse(
p_content => l_blob_content,
p_file_name => 'dataset.txt',
p_file_type => apex_data_parser.c_file_type_csv
)
)
) raw_data;
-- Update the timings table with the end time
update timings set end_time = systimestamp where action = 'APEX_DATA_PARSER';
-- Clean up the collection
l_tab := t_tab();
-- JSON_TABLE
-- Insert the start time in the timings table
insert into timings values ('JSON_TABLE', systimestamp, null);
-- Bulk collect the file content
select rtrim(substr(column_value, 1, 7)) as id,
rtrim(substr(column_value, 8, 20)) as first_name,
rtrim(substr(column_value, 21, 20)) as first_name,
rtrim(substr(column_value, 41, 30)) as city,
rtrim(substr(column_value, 71, 30)) as country
bulk collect into l_tab
from (
select val as column_value
from json_table ('["'
|| replace(l_clob_content, chr(10), '","')
|| '"]', '$[*]'
columns (
val varchar2(4000) path '$'
)
)
) raw_data;
-- Update the timings table with the end time
update timings set end_time = systimestamp where action = 'JSON_TABLE';
-- Clean up the collection
l_tab := t_tab();
-- DBMS_LOB
-- Insert the start time in the timings table
insert into timings values ('DBMS_LOB', systimestamp, null);
l_len := dbms_lob.getlength(l_clob_content);
begin
if (dbms_lob.isopen(l_clob_content) != 1) then
dbms_lob.open(l_clob_content, 0);
end if;
l_amount := instr(l_clob_content, chr(10), l_offset);
while (l_offset < l_len)
loop
dbms_lob.read(l_clob_content, l_amount, l_offset, l_buffer);
l_rec.id := rtrim(substr(l_buffer, 1, 7));
l_rec.first_name := rtrim(substr(l_buffer, 8, 20));
l_rec.last_name := rtrim(substr(l_buffer, 21, 20));
l_rec.city := rtrim(substr(l_buffer, 41, 30));
l_rec.country := rtrim(substr(l_buffer, 71, 30));
l_tab(i) := l_rec;
l_offset := l_offset + l_amount;
i := i + 1;
end loop;
if (dbms_lob.isopen(l_clob_content) = 1) then
dbms_lob.close(l_clob_content);
end if;
end;
-- Update the timings table with the end time
update timings set end_time = systimestamp where action = 'DBMS_LOB';
end;
The results are displayed using this SQL query
select action,
to_char(extract(minute from (end_time - start_time)) * 60 + extract(second from (end_time - start_time)), '990D000')
as elapsed_time_seconds
from timings
order by 2 asc
The results are
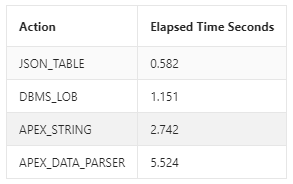
As you can see, the clear winner is JSON_TABLE!
Conclusion
It was a funny thing to find a solution for reading these fixed-width delimited files and at first, JSON_TABLE wasn't an option in my head. My first attempt was to use the dmbs_lob package, but then I remembered Tom Kyte's mantra (Slow by slow...):
My mantra, that I'll be sticking with thank you very much, is:
You should do it in a single SQL statement if at all possible.
If you cannot do it in a single SQL Statement, then do it in PL/SQL.
If you cannot do it in PL/SQL, try a Java Stored Procedure.
If you cannot do it in Java, do it in a C external procedure.
If you cannot do it in a C external routine, you might want to seriously think about why it is you need to do it…




